 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Person Re-Identification with Wireless Positioning under Weak Scene Labeling
Oct 29, 2021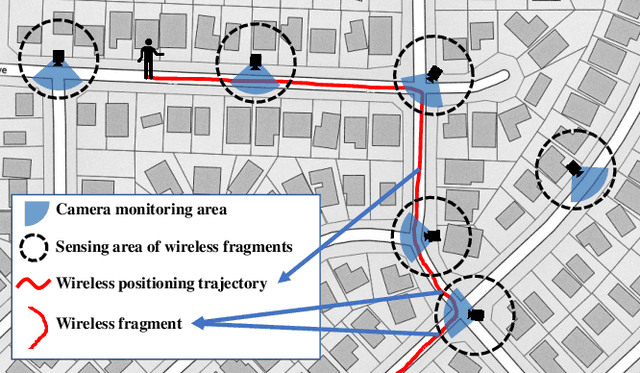


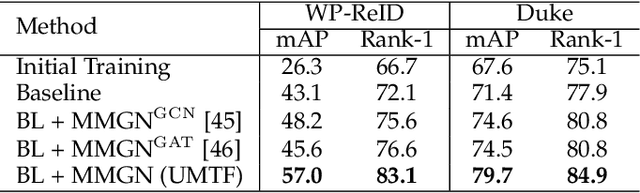
Existing unsupervised person re-identification methods only rely on visual clues to match pedestrians under different cameras. Since visual data is essentially susceptible to occlusion, blur, clothing changes, etc., a promising solution is to introduce heterogeneous data to make up for the defect of visual data. Some works based on full-scene labeling introduce wireless positioning to assist cross-domain person re-identification, but their GPS labeling of entire monitoring scenes is laborious. To this end, we propose to explore unsupervised person re-identification with both visual data and wireless positioning trajectories under weak scene labeling, in which we only need to know the locations of the cameras. Specifically, we propose a novel unsupervised multimodal training framework (UMTF), which models the complementarity of visual data and wireless information. Our UMTF contains a multimodal data association strategy (MMDA) and a multimodal graph neural network (MMGN). MMDA explores potential data associations in unlabeled multimodal data, while MMGN propagates multimodal messages in the video graph based on the adjacency matrix learned from histogram statistics of wireless data. Thanks to the robustness of the wireless data to visual noise and the collaboration of various modules, UMTF is capable of learning a model free of the human label on data. Extensive experimental results conducted on two challenging datasets, i.e., WP-ReID and DukeMTMC-VideoReID demonstrate the effectiveness of the proposed method.
Progressive Unsupervised Person Re-identification by Tracklet Association with Spatio-Temporal Regularization
Oct 25, 2019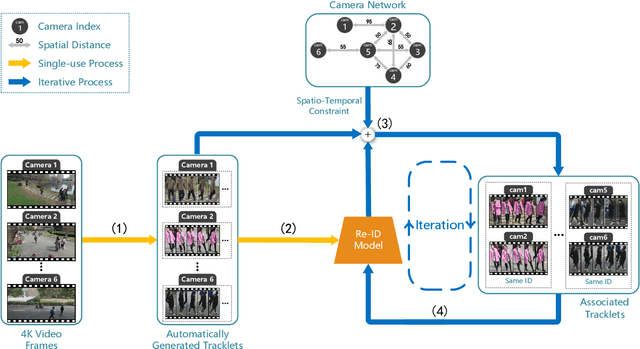


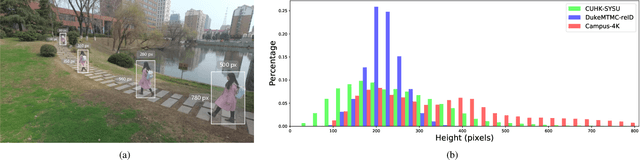
Existing methods for person re-identification (Re-ID) are mostly based on supervised learning which requires numerous manually labeled samples across all camera views for training. Such a paradigm suffers the scalability issue since in real-world Re-ID application, it is difficult to exhaustively label abundant identities over multiple disjoint camera views. To this end, we propose a progressive deep learning method for unsupervised person Re-ID in the wild by Tracklet Association with Spatio-Temporal Regularization (TASTR). In our approach, we first collect tracklet data within each camera by automatic person detection and tracking. Then, an initial Re-ID model is trained based on within-camera triplet construction for person representation learning. After that, based on the person visual feature and spatio-temporal constraint, we associate cross-camera tracklets to generate cross-camera triplets and update the Re-ID model. Lastly, with the refined Re-ID model, better visual feature of person can be extracted, which further promote the association of cross-camera tracklets. The last two steps are iterated multiple times to progressively upgrade the Re-ID model.
WIDER Face and Pedestrian Challenge 2018: Methods and Results
Feb 19, 2019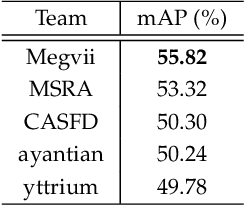

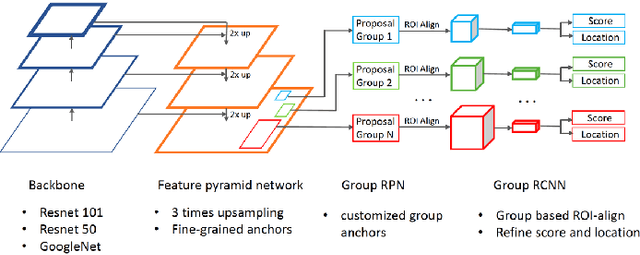
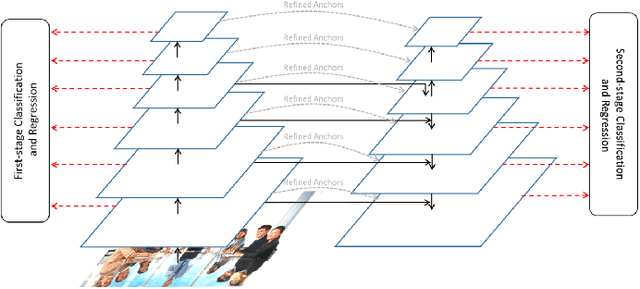
This paper presents a review of the 2018 WIDER Challenge on Face and Pedestrian. The challenge focuses on the problem of precise localization of human faces and bodies, and accurate association of identities. It comprises of three tracks: (i) WIDER Face which aims at soliciting new approaches to advance the state-of-the-art in face detection, (ii) WIDER Pedestrian which aims to find effective and efficient approaches to address the problem of pedestrian detection in unconstrained environments, and (iii) WIDER Person Search which presents an exciting challenge of searching persons across 192 movies. In total, 73 teams made valid submissions to the challenge tracks. We summarize the winning solutions for all three tracks. and present discussions on open problems and potential research directions in these topics.